数据结构复试面试
本文共 971 字,大约阅读时间需要 3 分钟。
数组和链表的区别
1.最重要的区别是数组在定义的时候就应该固定好了长度,而链表对于长度是不固定的。因此数组不适合于动态增减的情况,而链表适合。
2.两者对于数据的操作,对于插入和删除,链表是比较合适的(关键在与找到插入删除的点),而对于数组来说,插入和删除是比较麻烦的,因为需要移动一部分的数据。 3.从内存存储空间来看,数组从栈中分配空间,对于程序员来说比较方便,但自由度小。而链表从堆中分配空间,自由度大但是申请管理比较麻烦。
二叉树和度为2的树的区别
1.二叉树的度可以为0,1和2,但是度为2的树的度只能是2.
2.二叉树的子树有左子树和右子树的区别,而度为2的树的子树左右没有分别。
链表相对于线性表的区别
更加方便对数据的插入和删除
单链表中,增加头结点的目的
为了方便运算的实现,让对第一个结点的操作和其他点一致
栈和队列的共同特点是
都是限制在端点处对数据进行插入和删除,栈是在一个端点进行处理,而队列是在一个端点插入,一个端点删除
两种基本的存储结构
线性存储结构和链式存储结构
链表和循环链表的优点
链表是在插入和删除的时候,不需要移动元素,但是不能随机查找到对应的元素。而循环链表的优点在于从任何一个点访问链表都可以访问完全部表。
数据的存储结构和逻辑结构
算法的五个特征
1.可行性 2.确定性3.有限性 4.输入 5.输出
关于各种各样的排序:

基本思想就是:选取一个关键字,通常是第一个。然后通过一趟排序,确定好这个关键字的最后的位置,并且将记录分为关键字的左右部分,左边比关键字要小,右边要比关键字大,随后对这两部分的子表以此使用该分类方法
一些会问到的排序:
1.当表元素距离最终位置不远,为节省时间,可以采用直接插入排序
2.当数据规模小的时候,选择直接插入排序或者选择排序 3.当基本有序的时候,,选直接插入排序和直接选择排序 4.当数据规模较大的时候,选择快速排序,快速排序的平均时间最短,但是在最坏情况时,是On2 5.堆排序所需要的辅助空间比快排要小,但是这个两个排序都不是稳定的。
dfs和bfs的区别
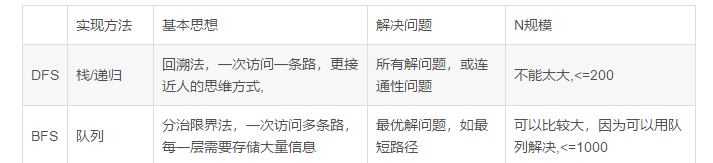
迪杰特斯拉算法和弗洛伊德算法的区别
从某个源点到其余各个顶点的最短路径问题:迪杰斯特拉(Dijkstra)算法。 图中所有到多有顶点的最短路径问题:弗洛伊德(Floyd)算法
转载地址:http://pkfen.baihongyu.com/
你可能感兴趣的文章
Datatables基本初始化——jQuery表格插件
查看>>
Servlet监听器——实现在线登录人数统计小例子
查看>>
Oracle笔记——简单查询语句 Oracle入门
查看>>
基于Hibernate和Struts2的用户管理系统小案例
查看>>
打开.class文件的方法
查看>>
基于windows平台Git+GitHub+Hexo搭建个人博客(一)
查看>>
基于windows平台Git+GitHub+Hexo搭建个人博客(二)
查看>>
Windows平台下SVN安装配置及使用
查看>>
python简便的编辑工具:jupyter notebook
查看>>
使用pip安装的时候出现 ModuleNotFoundError: No module named ‘pip‘
查看>>
Selenium自动化测试(八)之上传文件
查看>>
Selenium UI自动化(Java篇)
查看>>
使用Fiddler模拟弱网进行测试
查看>>
使用POI读取Excel测试用例
查看>>
记一次数据推送的异常解决端口解决
查看>>
linux、mysql、nginx、tomcat 性能参数优化
查看>>
Nginx使用Linux内存加速静态文件访问
查看>>
杀掉nginx进程后丢失nginx.pid,如何重新启动nginx
查看>>
nginx另类复杂的架构
查看>>
Nginx流量复制/AB测试/协程
查看>>